







- 綠色版查看
- 綠色版查看
- 綠色版查看
- 綠色版查看
- 綠色版查看
UMI-OCR軟件亮點
引擎與模型
PaddleOCR:默認使用 PPOCR-v3 模型,對常規文字、手寫體、傾斜文本識別率超 95%,但對低端 CPU(如奔騰/賽揚)兼容性較差。
RapidOCR:輕量級引擎,適配低端硬件,識別速度快但復雜背景處理稍弱。
混合識別:結合 EAST 或 DBNet 算法定位文字區域,再通過 PaddleOCR 或 Tesseract-OCR 轉換文本。
性能參數
速度:單張圖片識別耗時約 0.5-2 秒(取決于圖片復雜度和硬件配置)。
準確率:常規印刷體識別率超 95%,手寫體或粗體字可能出現誤判(如“畢竟”識別為“華竟”)。
資源占用:內存占用約 200-500MB,支持多任務并行處理。
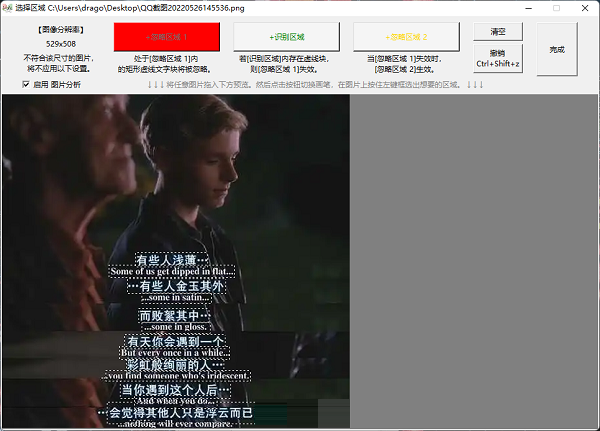
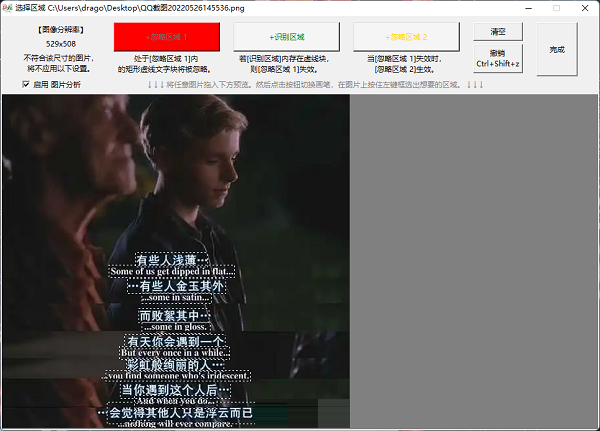
UMI-OCR軟件特色
日常辦公
快速提取合同、報告中的文字內容,支持批量處理以提高效率。
將掃描版 PDF 轉換為可編輯文檔,便于后續修改和檢索。
學習研究
識別書籍、論文中的文字,支持豎排文字和復雜排版優化。
提取課件中的關鍵信息,生成結構化文本。
隱私敏感場景
在無網絡環境下處理身份證、銀行卡等敏感信息,避免數據上傳風險。
識別企業內部機密文件,確保數據安全性。
開發者集成
提供命令行和 HTTP 接口調用,方便與其他軟件(如 Python 腳本、Web 應用)集成。
UMI-OCR軟件功能
離線運行與隱私保護
所有識別過程均在本地完成,避免數據泄露風險,尤其適合處理合同、證件等機密文件。
無需安裝,解壓即用,支持 Windows 7/10/11 系統(后續計劃擴展至 macOS 和 Linux)。
多場景識別能力
截圖 OCR:通過快捷鍵(默認 Ctrl+Alt+F)快速截取屏幕區域,支持動態調整識別范圍,0.73 秒內完成單張圖片識別。
批量處理:拖拽文件夾即可一次性識別上百張圖片(如 JPG、PNG、TIFF),輸出格式包括 TXT、Markdown、Excel 等,支持任務完成后自動關機。
PDF 處理:將掃描版 PDF 轉換為可搜索的雙層 PDF,保留原有排版,并可排除頁眉頁腳、水印等干擾元素。
二維碼功能:支持一圖多碼識別和批量生成,兼容 URL、文本、名片等 19 種編碼協議。
智能優化與細節處理
忽略區域:通過框選屏蔽水印、UI 元素等干擾信息(如視頻截圖右上角水印)。
排版解析:提供單行優化、自然段合并、代碼縮進保留等后處理方案,適配豎排文字、多欄排版等特殊格式。
多語言支持:內置中、英、日、韓等語言庫,通過擴展包可支持 80 余種語言(如俄語、德語、法語)。
UMI-OCR常見問題
Q:啟動時提示“缺少 Visual C++ 運行庫”怎么辦?
A:
下載并安裝 Microsoft Visual C++ Redistributable(與軟件版本匹配的 x64 或 x86 版本)。
若已安裝仍報錯,嘗試修復安裝或重新下載 UMI-OCR 完整包(可能文件損壞)。
Q:軟件閃退或無響應如何解決?
A:
低端 CPU 兼容性:若使用奔騰/賽揚等舊處理器,在設置中切換至 RapidOCR 引擎(輕量但功能稍弱)。
內存不足:關閉其他占用內存的程序,或增加虛擬內存(Windows 系統設置中調整)。
日志排查:查看軟件目錄下的 logs 文件夾,定位具體錯誤信息。
UMI-OCR更新日志
1.對部分功能進行了優化
2.解了好多不能忍的bug
華軍小編推薦:
UMI-OCR在行業內算是數一數二的軟件,相信有很多的小伙伴都會使用過的,你再不用就OUT了。本站還為您準備了Photo BlowUp、Adobe Illustrator CC、AutoCad 2020、美圖秀秀、ps下載中文版免費cs6














































您的評論需要經過審核才能顯示
有用
有用
有用